¿Qué son los Workload Objects en Kubernetes?
En Kubernetes, los Workload Objects (objetos de carga de trabajo) son los recursos que se encargan de gestionar y ejecutar tus aplicaciones dentro del clúster. Estos objetos definen cómo se crean, escalan y mantienen los Pods — la unidad mínima de ejecución en Kubernetes.
En lugar de crear Pods directamente, lo recomendado es usar estos objetos de mayor nivel que proporcionan capacidades como auto-recuperación, escalado, actualizaciones progresivas y más.
Los principales Workload Objects
1. Pod
El Pod es la unidad más pequeña y básica en Kubernetes. Representa uno o más contenedores que comparten red y almacenamiento.
- Cada Pod tiene su propia dirección IP
- Los contenedores dentro de un Pod comparten el mismo espacio de red (localhost)
- Generalmente no se crean Pods directamente en producción, sino a través de otros Workload Objects
apiVersion: v1
kind: Pod
metadata:
name: mi-app
spec:
containers:
- name: app
image: nginx:latest
ports:
- containerPort: 80
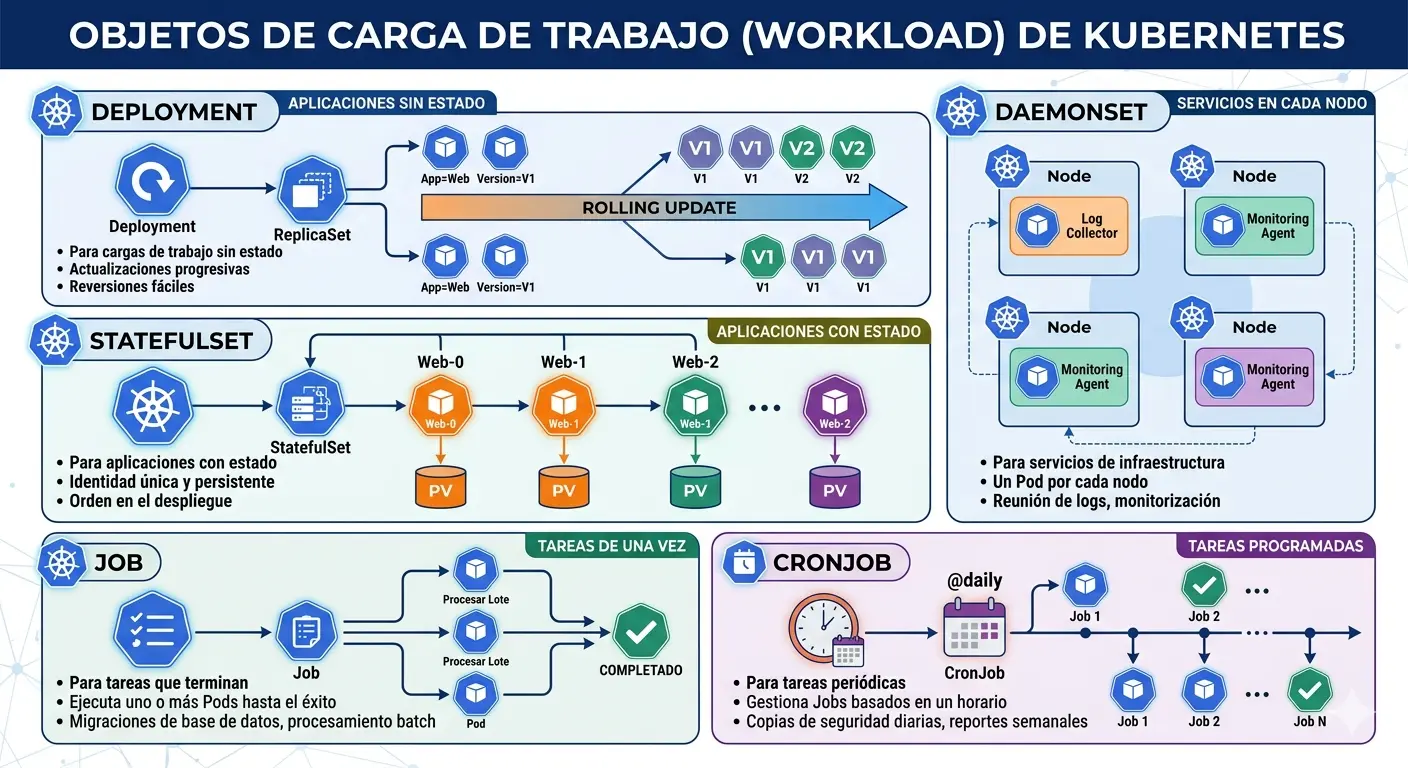
2. Deployment
El Deployment es el objeto más utilizado. Gestiona un conjunto de Pods idénticos (réplicas) y permite actualizaciones declarativas.
¿Para qué sirve?
- Mantener un número deseado de réplicas de tu aplicación
- Realizar rolling updates (actualizaciones sin downtime)
- Hacer rollbacks a versiones anteriores
- Escalar horizontal y automáticamente
apiVersion: apps/v1
kind: Deployment
metadata:
name: mi-deployment
spec:
replicas: 3
selector:
matchLabels:
app: mi-app
template:
metadata:
labels:
app: mi-app
spec:
containers:
- name: app
image: mi-imagen:v1
ports:
- containerPort: 80
3. ReplicaSet
El ReplicaSet garantiza que un número específico de réplicas de un Pod esté corriendo en todo momento.
¿Para qué sirve?
- Mantener la cantidad deseada de Pods activos
- Si un Pod falla, el ReplicaSet crea uno nuevo automáticamente
Nota: En la práctica, no se suelen crear ReplicaSets directamente. Los Deployments los gestionan de forma automática.
4. StatefulSet
El StatefulSet es similar a un Deployment, pero está diseñado para aplicaciones con estado (stateful) que necesitan identidad persistente y almacenamiento estable.
¿Para qué sirve?
- Bases de datos (MySQL, PostgreSQL, MongoDB)
- Sistemas de mensajería (Kafka, RabbitMQ)
- Aplicaciones que necesitan nombres de red estables y predecibles
- Almacenamiento persistente vinculado a cada Pod
Características clave:
- Cada Pod tiene un nombre único y ordenado (
pod-0,pod-1,pod-2) - Se crean y eliminan en orden secuencial
- Cada Pod puede tener su propio PersistentVolumeClaim
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mi-db
spec:
serviceName: "mi-db"
replicas: 3
selector:
matchLabels:
app: mi-db
template:
metadata:
labels:
app: mi-db
spec:
containers:
- name: postgres
image: postgres:15
volumeMounts:
- name: data
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 10Gi
5. DaemonSet
El DaemonSet asegura que una copia de un Pod se ejecute en todos (o algunos) nodos del clúster.
¿Para qué sirve?
- Agentes de monitoreo (Prometheus Node Exporter, Datadog)
- Agentes de logging (Fluentd, Filebeat)
- Herramientas de red (kube-proxy, CNI plugins)
- Agentes de seguridad
Cuando se agrega un nuevo nodo al clúster, el DaemonSet automáticamente despliega el Pod en ese nodo.
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: agente-monitoreo
spec:
selector:
matchLabels:
app: monitoreo
template:
metadata:
labels:
app: monitoreo
spec:
containers:
- name: node-exporter
image: prom/node-exporter:latest
ports:
- containerPort: 9100
6. Job
El Job ejecuta uno o más Pods hasta que se completen exitosamente. A diferencia de un Deployment, un Job no mantiene los Pods corriendo indefinidamente.
¿Para qué sirve?
- Migraciones de base de datos
- Procesamiento batch de datos
- Tareas de respaldo (backups)
- Cualquier tarea que deba ejecutarse una vez y terminar
apiVersion: batch/v1
kind: Job
metadata:
name: migracion-db
spec:
template:
spec:
containers:
- name: migrar
image: mi-app:latest
command: ["python", "manage.py", "migrate"]
restartPolicy: Never
backoffLimit: 3
7. CronJob
El CronJob crea Jobs de forma programada, siguiendo la sintaxis cron de Linux.
¿Para qué sirve?
- Backups programados
- Envío de reportes periódicos
- Limpieza de datos temporales
- Tareas de mantenimiento recurrentes
apiVersion: batch/v1
kind: CronJob
metadata:
name: backup-diario
spec:
schedule: "0 2 * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: backup
image: mi-backup:latest
command: ["./backup.sh"]
restartPolicy: OnFailure
Resumen
| Workload Object | Uso principal |
|---|---|
| Pod | Unidad básica de ejecución |
| Deployment | Apps stateless con rolling updates |
| ReplicaSet | Mantener réplicas (gestionado por Deployments) |
| StatefulSet | Apps con estado (bases de datos) |
| DaemonSet | Un Pod por nodo (monitoreo, logging) |
| Job | Tareas que se ejecutan una vez |
| CronJob | Tareas programadas periódicamente |
Elegir el Workload Object correcto es clave para diseñar aplicaciones robustas y eficientes en Kubernetes. Cada uno tiene su propósito y entender cuándo usar cada tipo te ahorrará muchos dolores de cabeza en producción.